What is Kubernetes?
Kubernetes is a comprehensive distributed system support platform. It features robust cluster management capabilities, including multi-layered security protection and admission control mechanisms, multi-tenant application support, transparent service registration and discovery mechanisms, built-in intelligent load balancers, powerful fault detection and self-healing capabilities, service rolling upgrades and online scaling capabilities, scalable resource auto-scheduling mechanisms, and fine-grained resource quota management capabilities. At the same time, Kubernetes provides a complete set of management tools covering various stages including development, testing deployment, and operation monitoring; therefore, Kubernetes is a new distributed architecture solution based on container technology and serves as a comprehensive distributed system development and support platform.
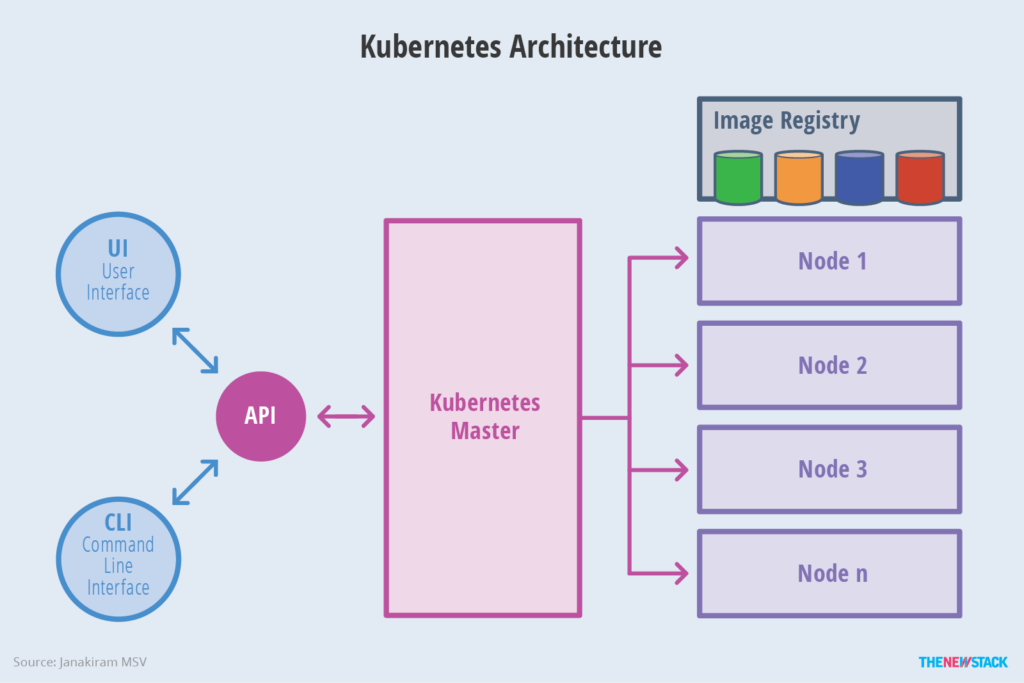
Kubernetes Architecture Diagram
Introduction to Kubernetes Basic Services
Here we only briefly introduce the basic components of Kubernetes, detailed explanations will be provided in subsequent articles!
Introduction to Kubernetes Services
Service is the core of a distributed cluster architecture. A Service object has the following key features:
- It has a uniquely specified name (e.g., mysql-server).
- It has a virtual IP (Cluster IP, Service IP, or VIP) and port number.
- It can provide certain remote service capabilities.
- It is mapped to a group of container applications that provide this service capability.
Currently, the service processes of a Service are based on Socket communication method for providing services externally, such as redis, memcache, MySQL, Web Server, or a specific TCP Server process implementing a specific business. Although a Service is usually provided by multiple related service processes, each service process has an independent Endpoint (IP+Port) access point, Kubernetes allows us to connect to the specified Service through the Service’s virtual Cluster IP + Service Port, with Kubernetes’ built-in transparent load balancing and fault recovery mechanisms, regardless of how many backend service processes there are or whether a service process will be redeployed to another machine due to a failure, it will not affect our normal invocation of the service. More importantly, once this Service is created, it will not change anymore, which means that in the Kubernetes cluster, we no longer need to worry about the problem of the service’s IP address changing.
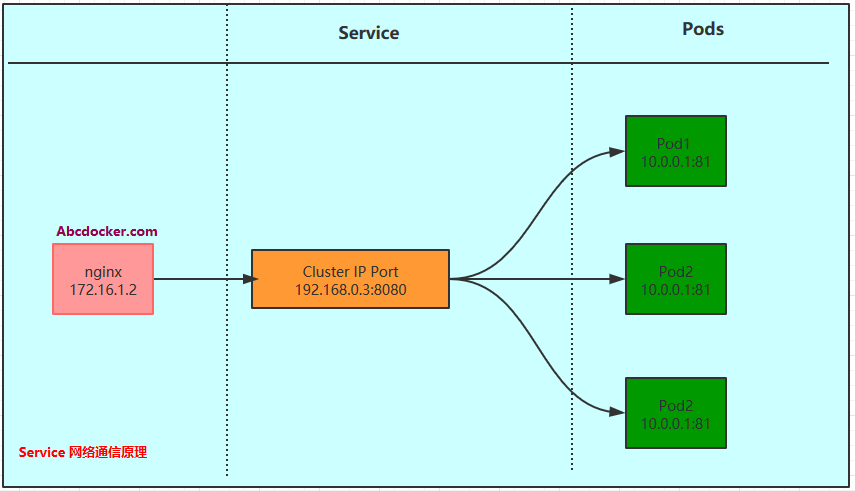
Server Access Diagram
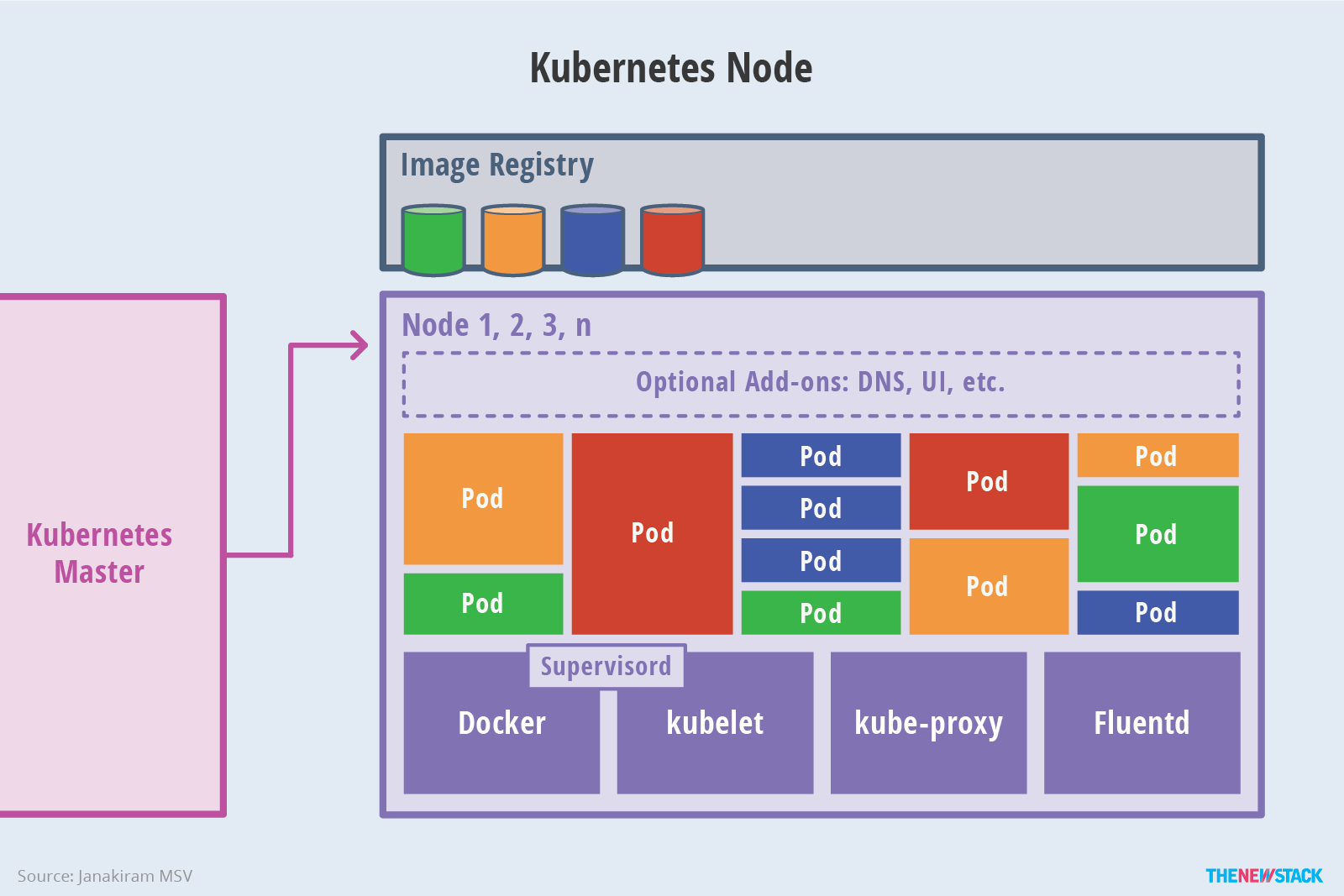
Introduction to Kubernetes Pods
Pod Concept: A Pod runs in an environment called a Node, which can be a private or public cloud virtual machine or physical machine. Usually, hundreds of Pods run on a single Node. Secondly, each Pod runs a special container called Pause, and other containers are business containers. These business containers share the network stack and Volume mounting volume of the Pause container, so communication and data exchange between them are more efficient. When designing, we can fully utilize this feature by placing a group of closely related service processes in the same Pod.
Not every Pod and the containers running inside it can be mapped to a Service. Only those groups of Pods that provide services (either internally or externally) will be mapped to a service.

Service and Pod Relationship
Containers provide powerful isolation, so it is necessary to isolate the group of processes that provide services for the Service into containers. Kubernetes designs the Pod object to wrap each service process into the corresponding Pod, making it a container running in the Pod. To establish the relationship between Service and Pod, Kubernetes first assigns a label to each Pod. For example, it assigns the name=mysql label to Pods running MySQL and the name=php label to Pods running PHP. Then, it defines label selectors for the corresponding Service, such as the label selector for the MySQL Service is name=mysql, which means that this Service will apply to all Pods containing the name=mysql label. This cleverly solves the problem of associating Service with Pods.
Introduction to Kubernetes Replication Controller (RC)
In a Kubernetes cluster, you only need to create an RC (Replication Controller) for Pods associated with a Service that needs to be scaled. This solves the headache of scaling up Services and subsequent Service upgrades, etc. Defining an RC file includes the following three key points:
- Definition of the target Pod
- Number of replicas of the target Pod to be run (Replicas)
- Label of the target Pod to be monitored
After creating the RC, the system automatically creates Pods based on the definition in the RC and monitors the status and quantity of the Pods that match the label defined in the RC in real-time. If the number of instances is less than the defined number of replicas (Replicas), Kubernetes will create a new Pod based on the Pod template defined in the RC, and then schedule this Pod to run on an appropriate Node until the number of Pod instances reaches the predetermined target. This process is completely automated and requires no human intervention. Just modify the number of replicas in the RC.
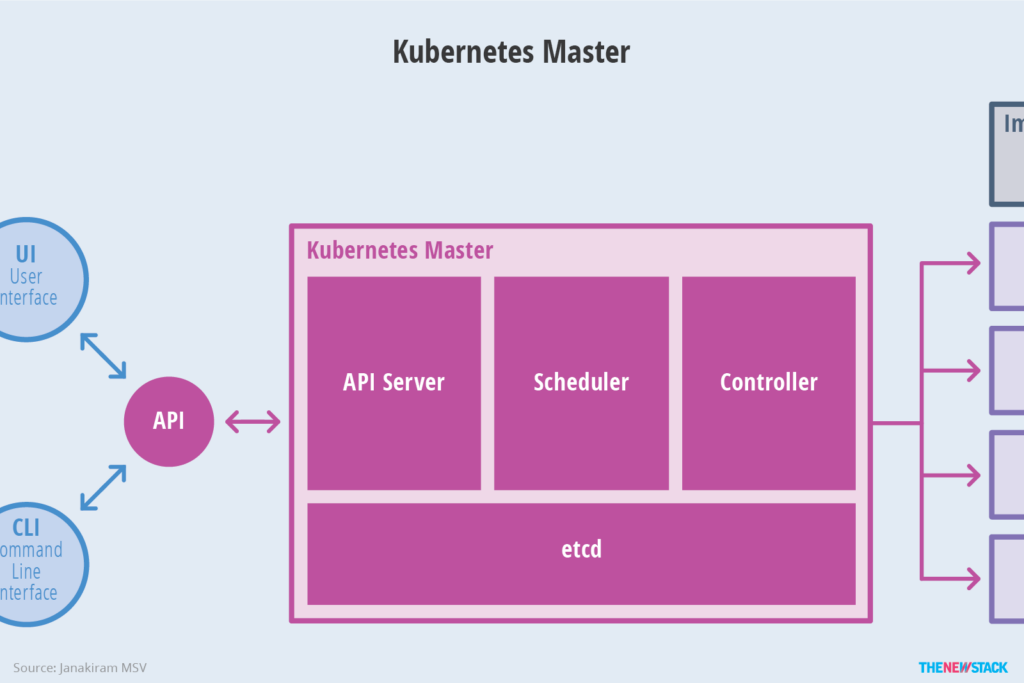
Introduction to Kubernetes Master
In Kubernetes, the Master refers to the cluster control node. Each Kubernetes cluster must have a Master node to manage and control the entire cluster. Essentially, all Kubernetes control commands are sent to it, and it is responsible for the specific execution process. Most of the commands we execute later run on the Master node. If the Master crashes or becomes unavailable, the management of the container cluster will be compromised.
The following key processes run on the Master node:
- Kubernetes API Server (kube-apiserver): Provides critical services with HTTP Rest interface, serving as the single entry point for all operations such as adding, deleting, modifying, and querying resources in Kubernetes, and also as the entry process for cluster control.
- Kubernetes Controller Manager (kube-controller-manager): The central control center for the automation of all resource objects in Kubernetes.
- Kubernetes Scheduler (kube-scheduler): Responsible for resource scheduling (Pod scheduling) process.
In addition, an etcd service needs to be started on the Master node, because all resource object data in Kubernetes is stored in etcd.
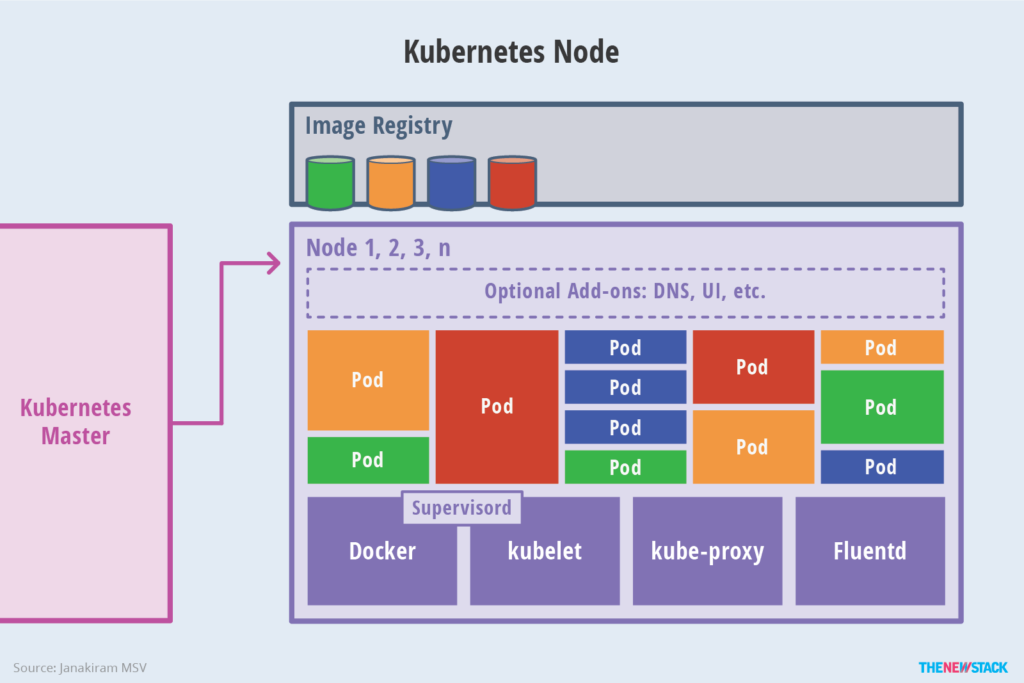
Introduction to Kubernetes Node
In addition to the Master, other machines in the cluster are called Node nodes. Each Node will be allocated some workload Docker containers by the Master. When a Node fails, the workload on it will be automatically transferred to other nodes by the Master.
The following key processes run on each Node node:
- kubelet: Responsible for tasks such as creating and stopping containers corresponding to Pods, and closely cooperating with the Master node to achieve basic cluster management functions.
- kube-proxy: An important component that implements communication and load balancing mechanisms for Kubernetes Service.
- Docker Engine (Docker): The Docker engine, responsible for creating and managing containers on the local machine.
Kubernetes Master and Node Responsibilities
In terms of cluster management, Kubernetes divides the machines in the cluster into a Master node and a group of worker nodes (Node). On the Master node, there is a set of processes related to cluster management, including kube-apiserver, kube-controller-manager, and kube-scheduler. These processes implement management functions such as resource management, Pod scheduling, elastic scaling, security control, system monitoring, and error correction for the entire cluster, all of which are fully automated. Nodes, as worker nodes in the cluster, run actual applications. The smallest running unit managed by Kubernetes on a Node is the Pod. On each Node, Kubernetes runs the kubelet and kube-proxy service processes, which are responsible for Pod creation, startup, monitoring, restart, destruction, and implementation of software-based load balancing.